NIFI 实现上一次任务执行完后,等待5分钟执行下一次任务

前两天在使用nifi进行数据同步的时候,原来的流程方式是设置使用GenerateFlowFile 作为初始节点,设置cron 表达式每5分钟执行一次。因为整个流程需要处理的节点比较多,有些数据查询会比较慢。虽然是数据增量的方式同步,但是存在当某次某节点查询的数据量过大,整个流程执行完超过5分钟的情况,此时下一次任务再次开始,就会导致最终插入的数据出现重复,这是业务不允许的,因此需要实现 实现上一次任务执行完后,等待5分钟执行下一次任务
方案一 (推荐)
使用 ExecuteScript Processor加上脚本的方式,实现延时5分钟。设置如下:
1、在配置界面的SETTINGS选项中设置Penalty duration 为300sec(5分钟)
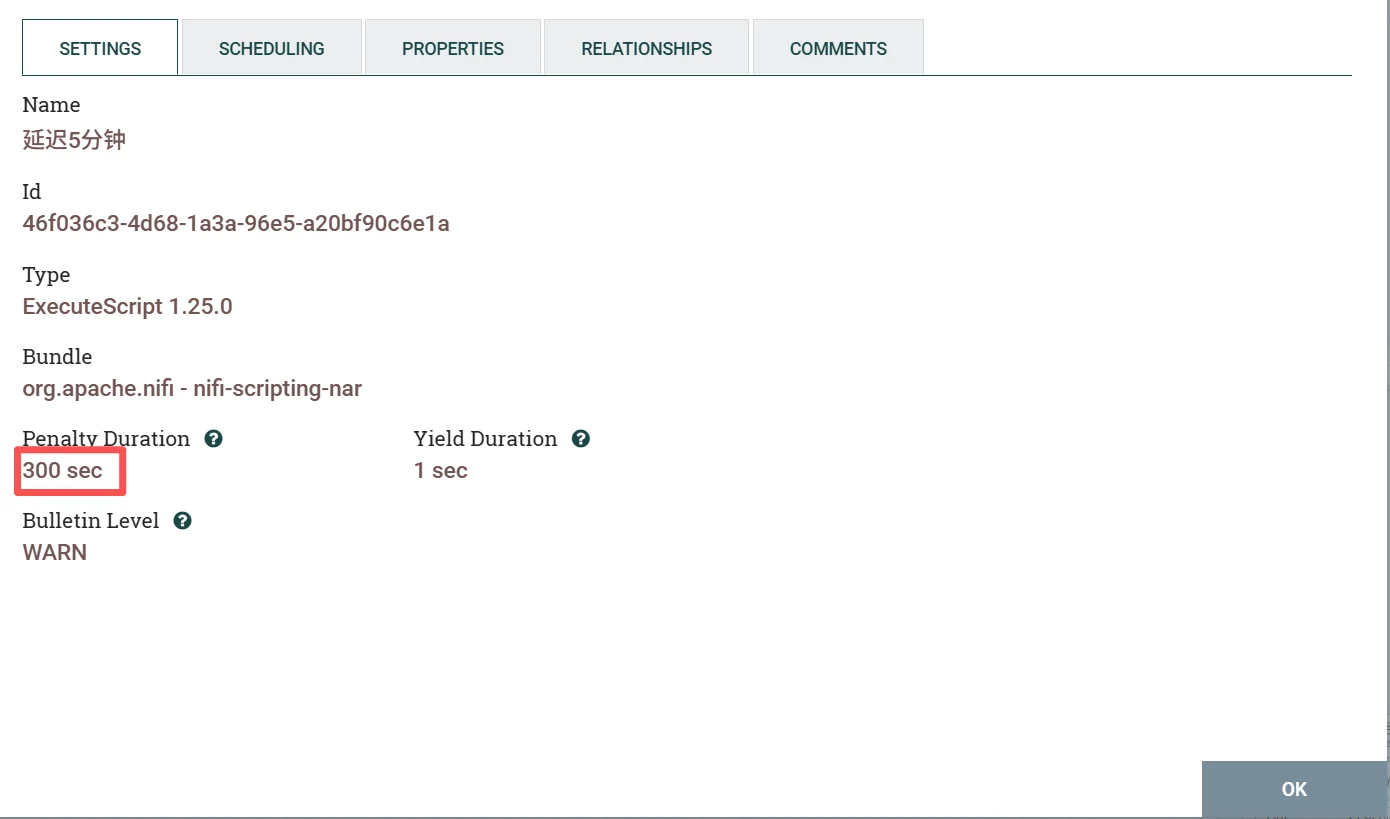
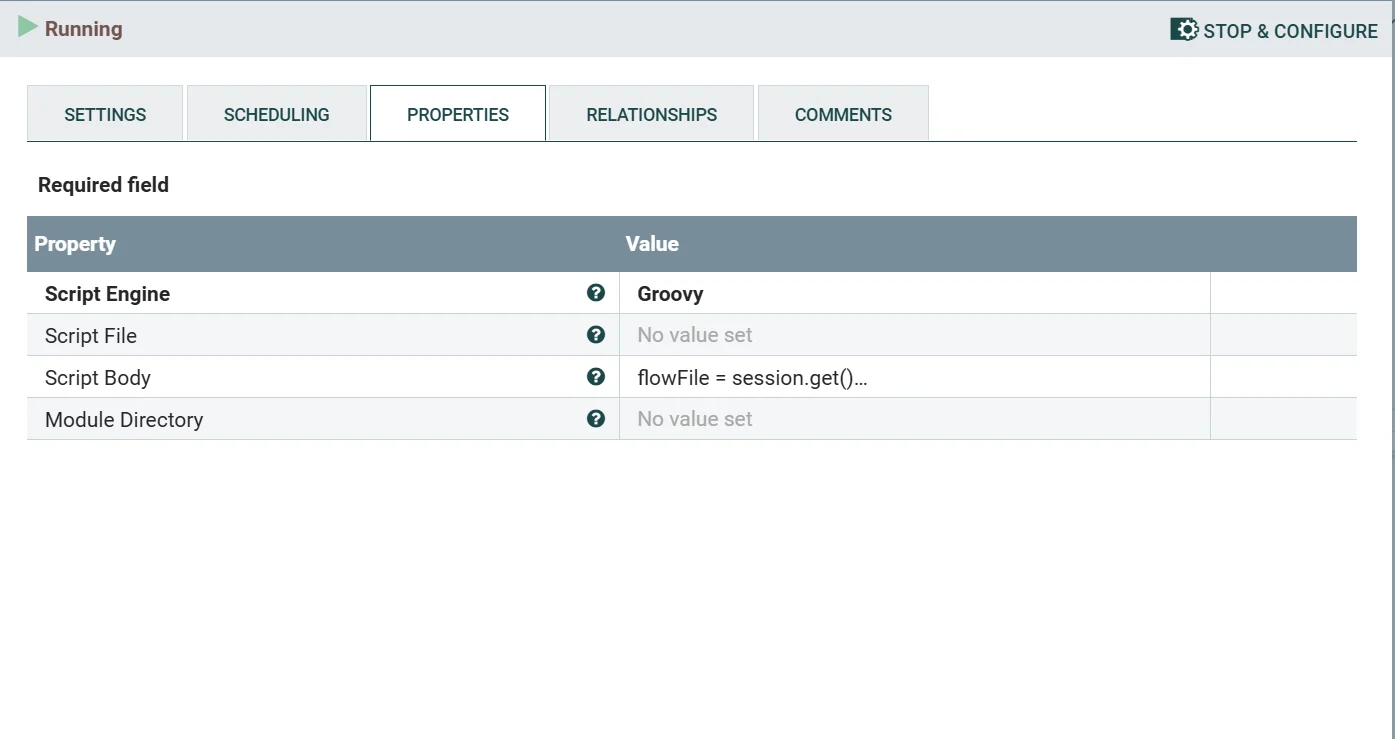
2、在配置界面的SETTINGS选项中,Script Engine 选择Groovy,在Script Body复制下面的脚本
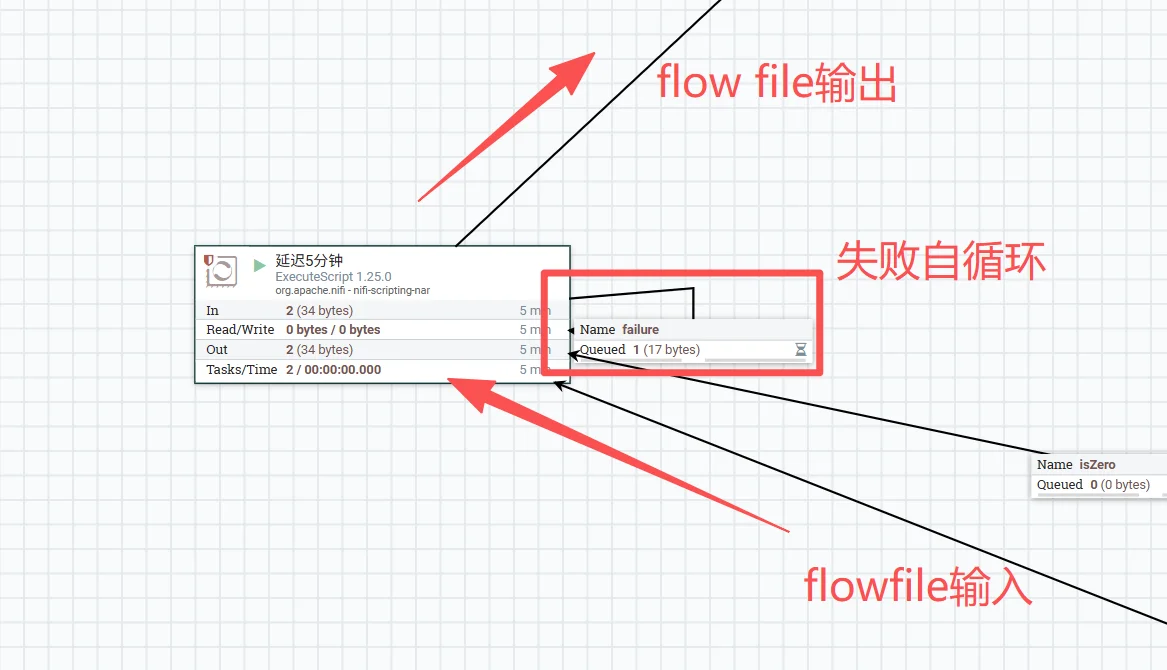
3、设置失败循环
方案二
利用处理组(Process Group)的并发控制(deepseek给出的方案,未实践,但觉得可行)
这是最直接、最符合NiFi设计理念的解决方案。它的核心思想是将整个数据同步流程封装起来,并严格控制同一时刻只能有一个“数据包”(即FlowFile)在流程组内处理。
创建处理组:将您除了
GenerateFlowFile之外的整个数据同步流程,封装到一个Process Group中。配置输入/输出端口:在处理组的边界,使用Input Port和Output Port来连接外部的
GenerateFlowFile和下游组件。关键配置:处理组策略
FlowFile Concurrency(流文件并发):将此选项设置为
Single batch at a time(单节点每次一个批次)。这确保了输入端口在一次处理中,会持续摄入数据直到馈送它的队列被清空,并且在组内所有数据处理完成并离开之前,不会带入新数据。Outbound Policy(出站策略):将此选项设置为
Batch output(批量输出)。这保证了只有在整个批次的所有数据都处理完毕,并在输出端口排队后,数据才会离开处理组。
通过以上组合设置,可以实现:只有当上一个由GenerateFlowFile触发的数据包被完全处理并输出后,处理组才会“接纳”下一个数据包。
方案三
构建一个流来创建您正在寻找的延迟
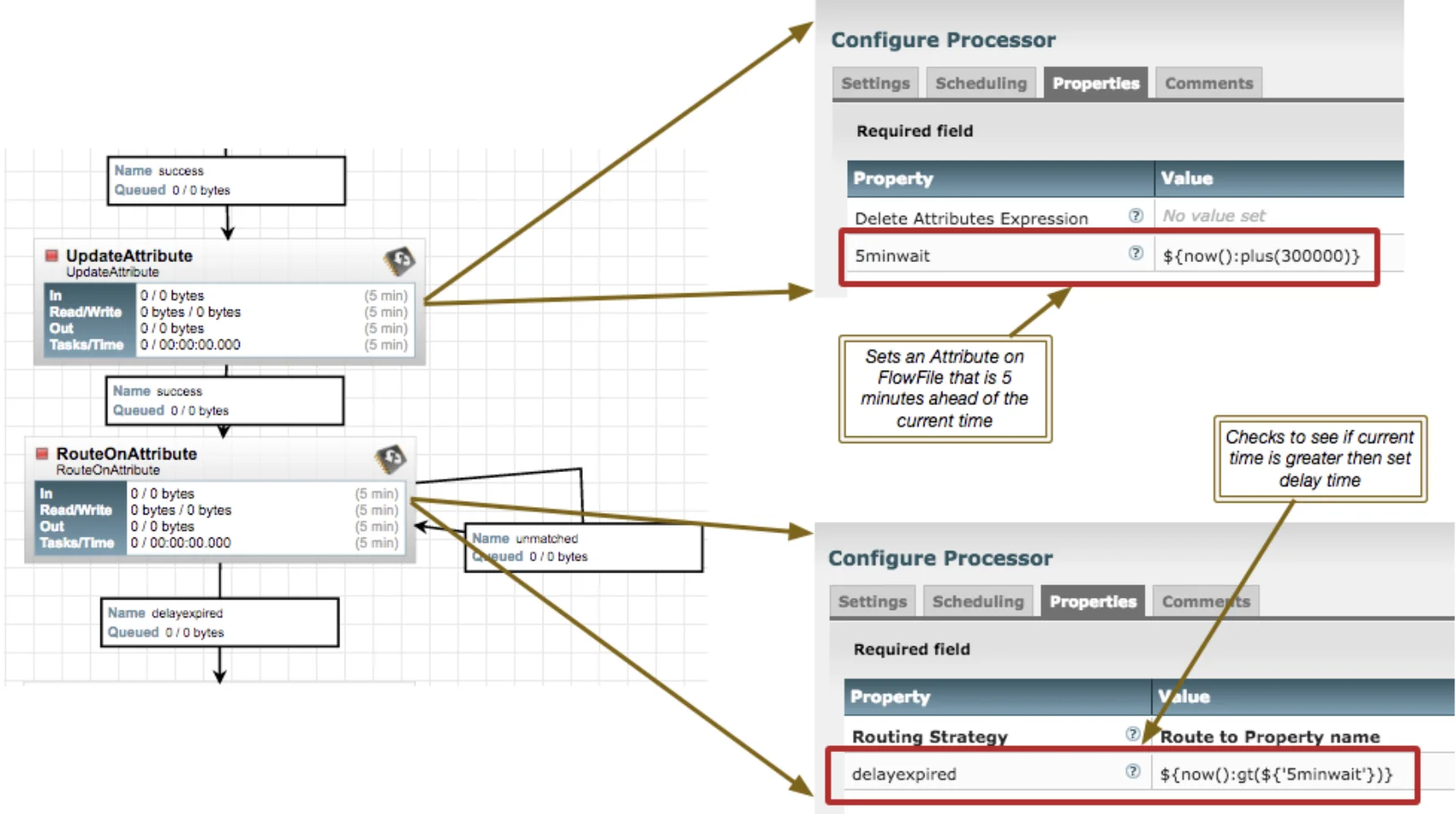
now() 函数返回的值是当前纪元时间(以毫秒为单位)。要增加 5 分钟,我们需要在当前时间上添加 300,000 毫秒,并将 tat 作为新属性存储在 FlowFile 上。然后,我们根据 routeOnAttribute 处理器中的当前时间检查该新属性。如果当前时间不大于延迟时间,则 FlowFile 将路由到不匹配。因此,这里的 FlowFile 将卡在这个循环中 ~5 分钟。您可以将 RouteOnAttribute 处理器上的运行计划调整到要重新检查文件的所需时间间隔。0 秒是默认值,但我建议将其更改为至少 1 秒
方案四
在数据专门建立一个表,写入一行数据来标记流程是否执行完
GenerateFlowFile开始输出flowfile后的第一个节点就去表里查询上一次任务的状态值下一个节点使用
EvaluateJsonPath绑定状态值在下一个节点使用
RouteOnAttribute进行判断,如果状态值为0,允许继续往下流flowfile文件,如果是1 ,不允许往下流flowfile文件。在最后任务完成后,需要增加一个
ExecuteSQLRecord去改写任务状态值。
存在的问题
因为流程比较长,涉及数据库操作,如果其中某个操作数据库的节点报错或者超时就会导致没有flowfile继续往下流,导致整个自循环的流程停滞。四种方案都存在这个问题的。使用时需要注意。
参考
1、已解决:NIFI 中有 WAIT 处理器吗?- Cloudera 社区 - 149077community.cloudera.c...